add penparse post
Deploy Website / build (push) Successful in 26s
Details
Deploy Website / build (push) Successful in 26s
Details
This commit is contained in:
parent
e66b5fc968
commit
b180d59328
|
|
@ -0,0 +1,64 @@
|
||||||
|
---
|
||||||
|
title: "Working on PenParse"
|
||||||
|
date: 2024-12-23T14:04:49Z
|
||||||
|
draft: true
|
||||||
|
description: A short update about my handwriting OCR project PenParse (formerly AnnoMemo)
|
||||||
|
url: /2024/12/23/penparse-update
|
||||||
|
type: posts
|
||||||
|
mp-syndicate-to:
|
||||||
|
- https://brid.gy/publish/mastodon
|
||||||
|
- https://brid.gy/publish/twitter
|
||||||
|
tags:
|
||||||
|
- post
|
||||||
|
- annomemo
|
||||||
|
- penparse
|
||||||
|
- python
|
||||||
|
- softeng
|
||||||
|
---
|
||||||
|
|
||||||
|
I'm currently working on PenParse (initially I called this [AnnoMemo](https://brainsteam.co.uk/2024/11/3/03-annomemo-telegram-bot/) ). It's a system for transcribing photos of handwritten notes into markdown notes and then adding them automatically to a personal knowledge management (PKM) app like [[Obsidian]] or [[Joplin]] or [[Memos]]. In other words it's a [Handwriting Text Recognition](https://en.wikipedia.org/wiki/Handwriting_recognition) (HTR) tool.
|
||||||
|
|
||||||
|
## Motivation for the project
|
||||||
|
|
||||||
|
Why work on this project? Well firstly, I love writing with pen and paper and also working with digital PKM apps. However, I am not a fan of typing up my notes or dictating my notes out loud to a speech-to-text program. The convenience of being able to take a photo of my notes and have them appear in obsidian is seductive. Furthermore, there seems to be appetite for it, per the recently announced initiative from Joplin around[integrating handwritten text recognition into their app](https://joplinapp.org/news/20241217-project-4-htr/).
|
||||||
|
|
||||||
|
Now is a good time to build this tool too. Local multi-modal language models like [Qwen2 VL](Qwen/Qwen2-VL-2B-Instruct) have gotten good enough at this task that we don't necessarily need to send any data (i.e. photos of your inner-most thoughts) to OpenAI or Anthropic for processing. Models like Qwen2 VL 2B can now run on an (admittedly high end) consumer laptop or graphics card and process a page of text in a few seconds.
|
||||||
|
|
||||||
|
The stakes of a model making a mistake are pretty low but the task is laborious, the sweet spot for this kind of tool. Effectively we're transcribing handwritten text that's going to end up as a note in Obsidian or a blog draft. If we store the extracted text next to the image of the handwritten note you can quickly check if something looks wrong and verify it by checking the image.
|
||||||
|
|
||||||
|
I'm also interested in building a completely opt-in, optional, voluntary HTR dataset which could be used to train smaller, more efficient HTR models, potentially opening up the possibility of running this pipeline completely locally on lower-end machines in the future. ***I cannot stress this enough: Participation in this dataset would be completely optional and opt in.*** I won't ever build a tool that gobbles up your innermost thoughts automatically without consent and you don't have to trust me, you'll be able to read the source code of the application and see that it's true. I plan on adding some friction to the process of submitting to this dataset so that people don't accidentally end up doing it. If that means we don't collect many samples then meh, so be it!
|
||||||
|
|
||||||
|
I've written in more detail about the project and my philosophy and choices [over on my digital garden](https://notes.jamesravey.me/Projects/PenParse).
|
||||||
|
|
||||||
|
## Progress so far
|
||||||
|
|
||||||
|
### Web App
|
||||||
|
|
||||||
|
I've taken the proof-of-concept that I built [a few weeks ago](https://brainsteam.co.uk/2024/11/3/03-annomemo-telegram-bot/) and started to build a web app around it using Django and Celery for running the image processing in the background. I've deliberately chosen to decouple the specific models from the application itself to give self-hosters the choice to use a third party API if they want to and don't have the capability to run the model locally.
|
||||||
|
|
||||||
|
I've built out a simple dashboard where you can upload image files and analysis progress. You can see the image status, when it was last updated and if the scanning was successful you can see a snippet of the text.
|
||||||
|
|
||||||
|
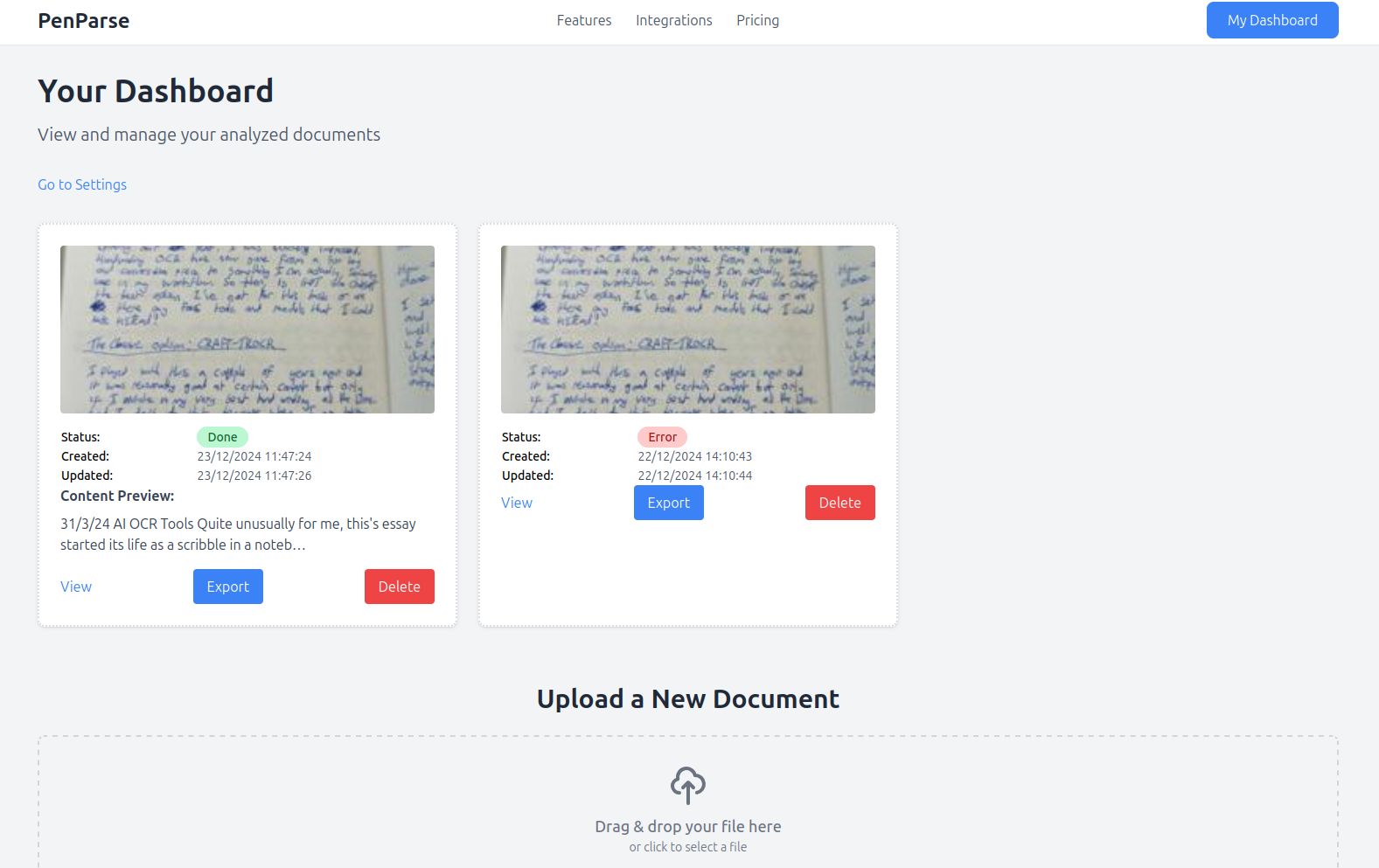
|
||||||
|
|
||||||
|
You can click 'View' on a card to see the full content. This view shows the full content that was extracted and also the image as it was scanned so that you can compare and contrast. You can also copy the note content to the clipboard.
|
||||||
|
|
||||||
|
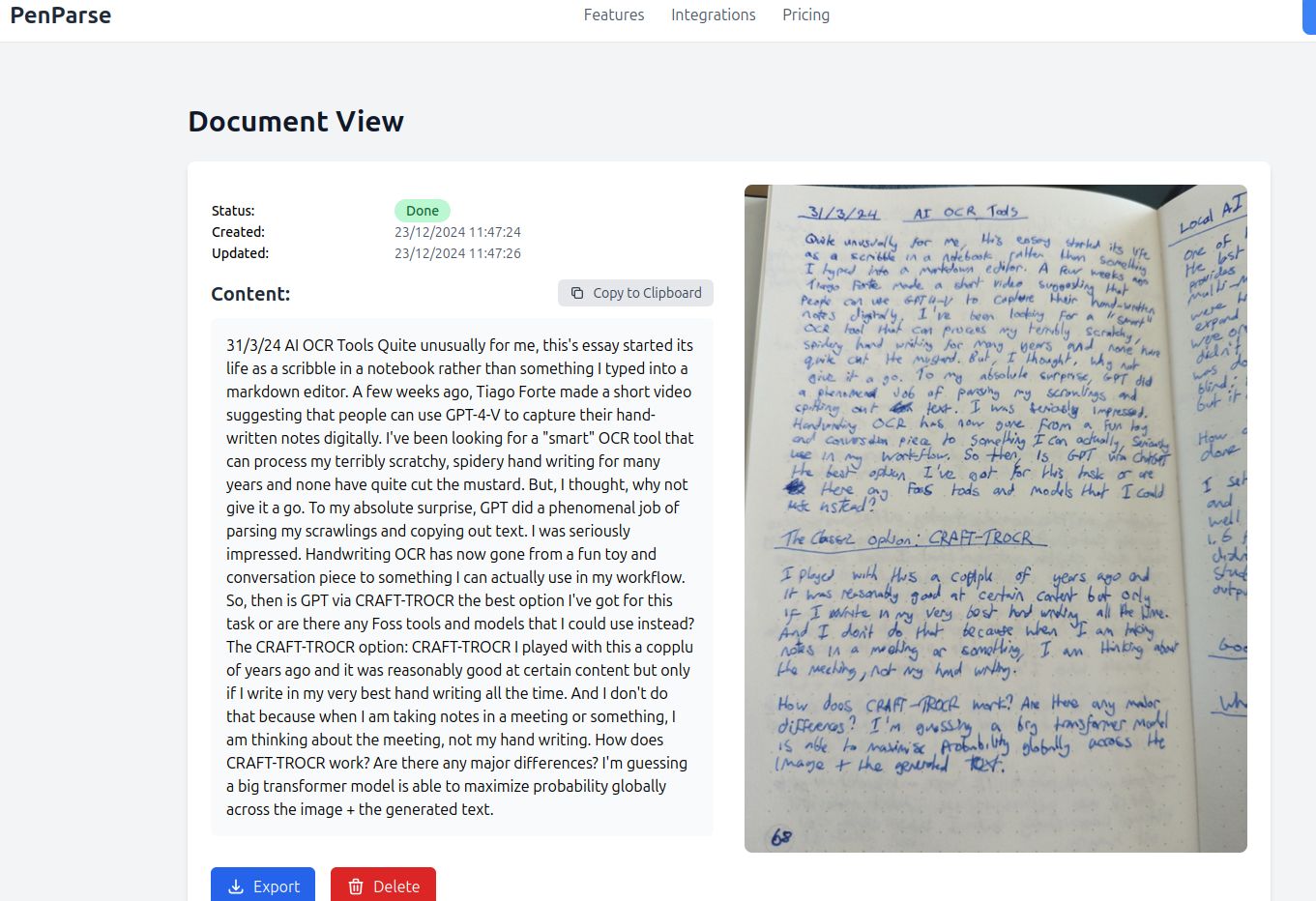
|
||||||
|
|
||||||
|
### API
|
||||||
|
|
||||||
|
I'm working on adding a REST api to the app using [django rest framework](https://www.django-rest-framework.org/tutorial/quickstart/), this will allow me to code up some plugins for common PKM apps fairly quickly. Users can currently authenticate via an API key.
|
||||||
|
|
||||||
|
## Plans and Next Steps
|
||||||
|
|
||||||
|
My next steps are likely to be writing some rudimentary plugins for Obsidian and possibly Joplin to prove the end-to-end concept and I'd also like to re-implement the Telegram bot functionality I built out in my proof-of-concept.
|
||||||
|
|
||||||
|
The flow would be:
|
||||||
|
|
||||||
|
1. User writes their note in their notebook
|
||||||
|
2. User opens up their smartphone and opens Telegram (or other chat app) or simply navigates to their PenParse instance from their browser
|
||||||
|
3. User snaps a photo of their note and uploads it to PenParse
|
||||||
|
4. Photo is processed in the background and information is extracted
|
||||||
|
5. Note + original photo are synced to the PKM app
|
||||||
|
6. User opens PKM app in their smartphone or on their laptop and the note text is visible.
|
||||||
|
|
||||||
|
I am building the project in [my private Forgejo instance](https://git.jamesravey.me/ravenscroftj/PenParse). I'm interested in feedback and comments and if anyone is keen on getting involved, let me know, PRs welcome!
|
||||||
Loading…
Reference in New Issue