9.5 KiB
| date | description | mp-syndicate-to | preview | tags | title | type | url | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2025-02-15 14:02:40+00:00 | How to self-host a personal archive of web content even if stuff get's taken down |
|
/social/9324906f536b6d0ce2d1a3c7bebdf620d72cb6900d2fa0a8f9bec8c3857e0970.png |
|
Building a Personal Archive With Hoarder | posts | /2025/2/15/personal-archive-hoarder |
In this day and age, what with gestures at everything it's important to preserve and record information that may be removed from the internet, lost or forgotten. I've recently been using Hoarder to create a self-hosted personal archive of web content that I've found interesting or useful. Hoarder is an open source project that runs on your own server and allows you to search, filter and tag web content. Crucially, it also takes a full copy of web content and stores it locally so that you can access it even if the original site goes down.
A Brief Review of Hoarder
Hoarder runs a headless version of Chrome (i.e. it doesn't actually open windows up on your server, it just simulates them) and uses this to download content from sites. In the case of paywalled content (maybe you want to save down a copy of a newspaper article for later reference), it can work with SingleFile which is a browser plugin for Chrome and Firefox (including mobile) that sends a full copy of what you are currently looking at in your browser to Hoarder. That means that even if you are looking at something that you had to log in to get to, you can save it to Hoarder without having to share any credentials with the app.
Hoarder optionally includes some AI Features which you can enable or disable depending on your disposition. These features allow hoarder to automatically generate tags for the content you save and optionally generate a summary of any articles you save down too. By default, Hoarder works with OpenAI APIs and, they recommend using gpt-4o-mini. However, I've found that Hoarder will play nicely with my LiteLLM and OpenWebUI setup meaning that I can generate summaries and tags for bookmarks on my own server using small language models, minimal electricity, no water and without Sam Altman knowing what I've bookmarked.
The web app is pretty good. It provides full-text search over the pages you have bookmarked and filtering by tag. It also allows you to create lists or 'feeds' which are based on sets of tags you are interested in. Once you click in to an article you can see the cached content and optionally generate a summary of the page. You can manually add tags and, you can also highlight and annotate the page inside hoarder.
Hoarder also has an Android app which allows you to access your bookmarked content from your phone. The app is still a bit bare-bones and does not appear to let you see the cached/saved content yet, but I imagine it will get better with time.
Hoarder is a fast-evolving project that has only turns 1 year old in the next couple of weeks. It has a single lead maintainer who is doing a pretty stellar job given that it's his side-gig.
Setting Up Hoarder
I primarily use docker and docker-compose for my self-hosted apps. I followed the developer-provided instructions to get hoarder up and running. Then, in the .env file we provide some slightly different values for the openai api base URL, key and the inference models we want to use.
By default, Hoarder will pull down the page, attempt to extract and simplify the content and then throw away the original content. If you want Hoarder to keep a full copy of the original content with all bells and whistles, set CRAWLER_FULL_PAGE_ARCHIVE to true in your .env file. This will take up more disk space but means that you will have more authentic copies of the original data.
You'll probably want to set up a HTTP reverse proxy to forward requests to hoarder to the right container. I use Caddy because it is super easy and has built in lets-encrypt support:
hoarder.yourdomain.example {
reverse_proxy localhost:3011
}
Once that's all set up, you can log in for the first time. Navigate to user settings and go to API Keys, you'll need to generate a key for browser integration.
Configuring SingleFile and the Hoarder Browser Extension
I have both SingleFile and Hoarder Official Extension installed in Firefox. Both extensions have their place in my workflow, but you might find that your mileage varies. By default, I'll click through into the Hoarder extension which has tighter integration with the server and knows if I already bookmarked a page. If I'm logged into a paywalled page or, I had to click through a load of cookie banners and close a load of ads, I'll use SingleFile.
For the Hoarder Extension, click on the extension and then simply enter the base URL of your new instance and paste your API key when prompted. The next time you click the button it will try to hoard whatever you have open in that tab.
For SingleFile you can follow the guidance here. Essentially you'll want to right click on the extension icon and go to 'Manage Extension' and then open Preferences, expand Destination and then enter the API URL (https://YOUR_SERVER_ADDRESS/api/v1/bookmarks/singlefile), your API key (which you generated above and used for the Hoarder extension) and then set data field name to file and URL field name to url.
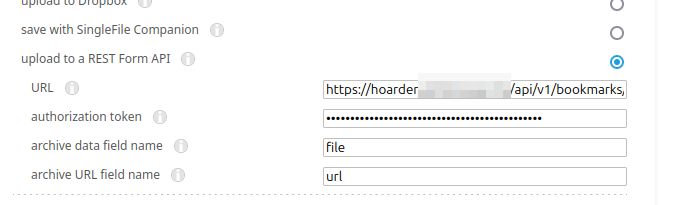 .
.
Once you've done this, the next time you click the SinglePage extension icon, it should work through multiple steps to save the current page including any supporting images to Hoarder.
Adding Self-Hosted AI Tags and Summaries with LiteLLM
I already have a litellm instance configured, you can refer to my earlier post for hints and tips on how to get this working. See the following example and replace litellm.yourdomain.example and your-litellm-admin-password with the corresponding values from your setup.
OPENAI_BASE_URL=https://litellm.yourdomain.example
OPENAI_API_KEY=<your-litellm-admin-password>
INFERENCE_TEXT_MODEL="qwen2.5:14b"
INFERENCE_IMAGE_MODEL=gpt-4o-mini
I also found that there is a quirk of LiteLLM which means that you have to use ollama_chat as the model prefix in your config rather than ollama to enable error-free JSON and model 'tool usage'. Here's an excerpt of my LiteLLM config yaml:
- model_name: gpt-4o-mini
litellm_params:
model: openai/gpt-4o-mini
api_key: "os.environ/OPENAI_API_KEY"
- model_name: qwen2.5:14b
litellm_params:
drop_params: true
model: ollama_chat/qwen2.5:14b
api_base: http://ollama:11434
I don't have any local multi-modal models that both a) work with the LiteLLM and b) actually do a good job of answering prompts, so I still rely on gpt-4o-mini for vision based tasks within hoarder.
Migrating from Linkding
I have been using Linkding for bookmarking and personal archiving until very recently but I wanted to try Hoarder because I'm easily distracted by shiny things. There is no official path for migrating from Linkding to Hoarder as far as I can tell but I was able to use Linkding's RSS feed feature for this purpose.
First, I logged into my linkding instance and navigated to Settings > Integrations and grabbed the RSS feed link for All bookmarks
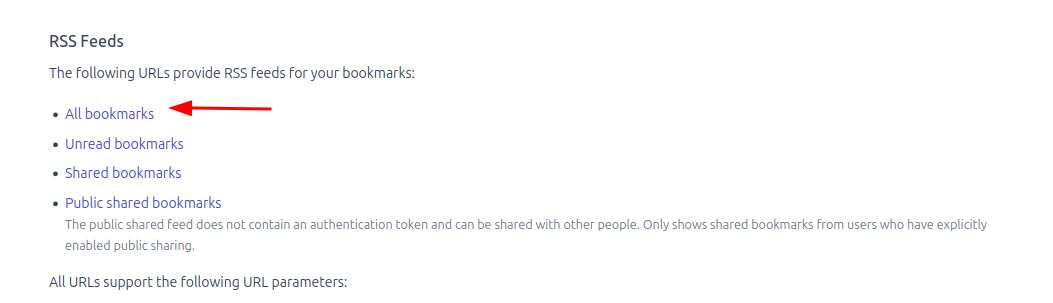 .
.
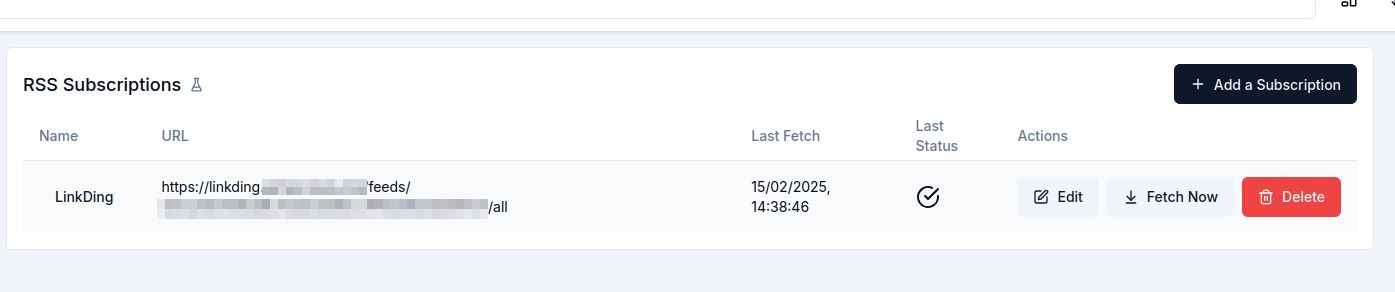
Then, I opened up Hoarder's User Settings > RSS Subscriptions and added my feed as a subscription there. I clicked "Fetch Now" to trigger an initial import.
Conclusion
Hoarder is a pretty cool tool and, it's been easy to get up and running with. It's quickly evolving despite the size of the team behind it and it provides an impressive and easy user experience already. In order to become even more useful for me personally, I'd love to see better annotation support in-app both via the desktop web experience and via the mobile app. I'd also love to see a mobile app with features for reading articles in-app rather than opening things in the browser. Also, it would be great if we could export cached content as an ebook so that I can read bookmarked content on my kindle or my kobo.
I'd also be interested in a decentralised social future for apps like hoarder. Imagine if you could join a federation of Hoarder servers which all make their bookmarked content available for search and reference. Annotations and notes could even (optionally) be shared. This would be a great step towards a more open alternative to centralized search services.